
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- SQL
- groupby
- 오블완
- 안드로이드
- 기술면접
- 혼공챌린지
- Til
- 알고리즘
- 프로그래머스
- 자료구조
- 카카오코테
- 인프런
- select
- CS
- 자바
- java
- Kotlin
- doitandroid
- MySQL
- 안드로이드스튜디오
- 혼공파
- 정보처리기사
- 티스토리챌린지
- 정처기
- Android
- 스터디
- 코테
- 혼공단
- 코틀린
- join
Archives
- Today
- Total
Welcome! Everything is fine.
[DB] UNION, UNION ALL, UNION 정렬 본문
728x90
인프런 <김영한의 실전 데이터베이스 - 기본편> 강의를 토대로 정리한 내용입니다.
UNION
UNION은 여러 개의 결과 집합을 아래로(수직으로) 이어 붙여서 더 많은 행을 가진 집합으로 만드는 기술이다.
- UNION으로 연결되는 모든 SELECT문은 컬럼의 개수가 동일해야 한다.
- 각 SELECT 문의 같은 위치에 있는 컬럼들은 서로 호환 가능한 데이터 타입이어야 한다. (이름은 달라도 됨)
- 최종 결과의 컬럼 이름은 첫번째 SELECT 문의 컬럼 이름을 따른다.
- 중복되는 행은 자동으로 제거한다. → UNION ALL을 사용하면 의도적으로 중복을 허용할 수 있다.
아래 예시를 보면, 활동 고객 명단(users)과 탈퇴 고객 명단(retired_users)을 합쳤다. UNION은 기본적으로 두 결과 집합을 합친 뒤, 완전히 중복되는 행은 자동으로 제거하여 고유한 값만 남긴다.
select name, email from users
union
select name, email from retired_users;UNION ALL
UNION ALL은 여러 개의 결과 집합을 아래로(수직으로) 이어 붙여 하나의 결과 집합으로 만든다. 중복 행을 제거하지 않고, 모든 행을 그대로 포함한다.
두 종류의 고객에게 이메일을 보내려고 할 때, 첫 번째 그룹은 '전자기기' 카테고리의 상품을 구매한 이력이 있는 고객이고, 두 번째 그룹은 '서울'에 거주하는 고객이다. '서울'에 살면서 '전자기기'를 구매한 고객을 최종 목록에 한 번만 포함할지, 중복을 허용할지에 따라 UNION을 쓸지, UNION ALL을 쓸지 결정할 수 있다.
먼저, UNION을 사용한 결과는 다음과 같다.
-- 전자기기 구매 고객
select u.name, u.email
from users u
inner join orders o on u.user_id = o.user_id
inner join products p on o.product_id = p.product_id
where p.category = '전자기기'
union
-- 서울 거주 고객
select name, email
from users
where address like '서울%';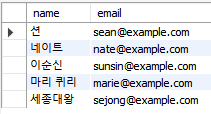
UNION ALL을 사용하면 '션', '네이트', '마리퀴리'가 중복되어 나타난다.
-- 전자기기 구매 고객
select u.name, u.email
from users u
inner join orders o on u.user_id = o.user_id
inner join products p on o.product_id = p.product_id
where p.category = '전자기기'
union all
-- 서울 거주 고객
select name, email
from users
where address like '서울%';
UNION vs UNION ALL
한 줄 요약 : UNION ALL이 훨씬 빠르다.
- UNION : 두 결과 집합을 합친 후,중복된 행을 제거한다.
- UNION ALL : 중복 제거 과정 없이, 두 결과 집합을 그대로 모두 합친다.
중복을 제거하는 추가 과정이 없는 UNION ALL이 훨씬 빠르다. 따라서 중복을 제거해야만 하는 명확한 요구사항이 있을 때만 UNION을 사용한다. 불필요한 UNION은 쿼리를 느리게 만들 수 있다.
UNOIN 정렬
ORDER BY 절은 전체 UNION 연산의 가장 마지막에 한 번만 사용해야 한다.
합쳐진 최종 결과 전체에 대한 순서를 결정해야 하기 때문에, ORBER BY 절의 위치가 중요하다.
다음과 같이 활동 고객과 탈퇴 고객의 명단을 합친 후 이름(name) 기준 오름차순 정렬을 하면, ORDER BY 절을 UNION 연산자의 마지막에 배치함으로써, 합쳐진 모든 고객의 이름이 글자 순서대로 정렬된다.
select name, email from users
union
select name, email from retired_users
order by name; -- 최종 결과에 대한 정렬
또한 각 테이블에 이름이 다른 컬럼이 있다면, 그 컬럼들을 아우를 수 있는 중립적인 별칭을 사용하는 것을 권장한다.
select distinct u.name as 고객명, u.email as 이메일
from users u
join orders o on u.user_id = o.user_id
join products p on o.product_id = p.product_id
where p.category = '전자기기'
union all
select distinct u.name as 고객명, u.email as 이메일
from users u
join orders o on u.user_id = o.user_id
where o.quantity > 1;'TIL' 카테고리의 다른 글
| [DB] 인덱스 생성 · 조회 · 삭제 및 실행 계획 보기(+ 인덱스로 정렬 작업 성능 개선하기) (1) | 2026.01.24 |
|---|---|
| [DB] 내부 조인, 외부조인, 셀프조인, 크로스조인 (0) | 2025.11.27 |
| [CS] 디자인 패턴 종류와 간단한 개념 정리 (0) | 2025.10.22 |
| [STUDY] '향로' 와 함께하는 추석 완강 챌린지 회고 🌕🏃🏻 (0) | 2025.10.14 |
| [TIL] 멀티 스레드 - 스레드와 스레드 풀 이해하기 (0) | 2025.09.11 |
'TIL' Related Articles
more
