
- 분류 전체보기 (387)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 카카오코테
- 정보처리기사
- Android
- 안드로이드스튜디오
- 프로그래머스
- 혼공챌린지
- 기술면접
- SQL
- 안드로이드
- select
- join
- 코테
- 알고리즘
- MySQL
- 자바
- 혼공파
- 코틀린
- doitandroid
- 스터디
- CS
- 오블완
- Til
- 정처기
- 혼공단
- 인프런
- 티스토리챌린지
- 자료구조
- groupby
- Kotlin
- java
- Today
- Total
Welcome! Everything is fine.
[Java/Study] 김영한의 실전 자바 중급 2편 - 스터디 14회차 본문
인프런 강의 <김영한의 실전 자바 - 중급 2편>을 보고 정리한 내용입니다.
매주 모여 각자 정리한 내용을 기반으로 발표하고 질문 공유하는 스터디입니다.
📘HashSet
해시 코드
해시 자료 구조에 데이터를 저장하는 경우 hashCode() 를 구현해야 한다!
해시 인덱스는 배열의 인덱스로 사용되기 때문에 양의 정수만 사용 가능하다. 따라서 문자 혹은 객체의 경우 hashCode() 메서드를 통해 고유한 숫자를 만들고, 그 숫자를 이용해 해시 인덱스를 만든다.
문자열의 경우, hashCode() 메서드를 통해 문자를 기반으로 고유한 숫자를 만든다. 강의에서는 'A' - 65, 'B' - 66, 'AB' - 131와 같이 아스키 코드를 통해 각 문자에 고유한 숫자를 할당해 계산했다. 실제 자바의 String.hashCode()는 다음과 같이 각 문자에 가중치를 적용하여 더 복잡한 연산을 수행한다.
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
객체의 경우도 마찬가지로 hashCode() 메서드를 통해 고유한 숫자를 만든다. Object 에 있는 hashCode() 메서드를 보통 오버라이딩해서 사용한다. 해당 메서드의 기본 구현은 객체의 참조값을 기반으로 해시 코드를 생성한다. 따라서 만약 id값으로 Member 객체를 구분하고 싶다고 하면, 반드시 hashCode()를 구현해줘야 제대로 구분할 수 있다. 구현하지 않으면 각 인스턴스 별로 해시코드가 다르기 때문에 같은 id라도 인스턴스가 다르면 제대로 구분되지 않는다.
public class Object {
public int hashCode();
}
✔️ Object의 기본 기능
- hashCode() : 객체의 참조값을 기반으로 해시 코드 반환
- equals() : == 동일성 비교를 해서 객체의 참조값이 같아야 true 반환
❓hash()와 hashCode() 차이
강의에서는 hash()를 사용했는데, IDE에서 생성된 걸 보니 hashCode()로 생성되었다. 그 차이가 무엇인지 궁금해서 찾아보았다.
private int hashIndex(Object value) {
return Math.abs(value.hashCode() % capacity);
}private int hashIndex(Object value) {
return Math.abs(value.hash() % capacity);
}- hashCode() : 객체 자체의 고유 해시코드를 반환하며, 해시 기반 자료구조에서 사용된다.(ex. id 기반으로 해시 코드 생성 시)
- Objects.hash() : 여러 필드를 기반으로 해시코드를 계산할 때 유용하며, 주로 hashCode() 메서드 구현을 단순화하는 데 사용된다.(ex. id와 name을 기반으로 해시 코드를 생성 시)
equals, hashCode의 중요성
해시 자료 구조 사용 시 equals()와 hashCode()를 반드시 구현해야 한다!
해시 자료 구조를 사용할 때 hashCode() 뿐만 아니라 해시 충돌을 대비해 equals() 역시 재정의가 필요하다. 해시 인덱스가 충돌하면 같은 해시 인덱스에 있는 데이터들을 하나하나 비교해야하는데, 이때 equals()를 사용하기 때문이다. 만약 특정 인덱스에 데이터가 하나만 있다고 하더라도 해시 인덱스와 실제 저장된 데이터는 다를 수 있기 때문에 equals()를 꼭 구현해야 한다.
- "JPA" 회원 / "hi" 회원의 해시 인덱스 : 0번
- "hi" 회원만 저장했을때, "JPA" 회원을 찾는다면?
- equals()를 구현했을 경우 -> 0번 인덱스에는 "hi" 회원만 존재하므로 검색 실패
- equals()를 구현하지 않았을 경우 -> 0번 인덱스에 있는 객체를 무작정 찾아서 "hi" 회원이 검색되는 오류 발생
이런 식으로 오류가 발생할 수 있는데, Object가 기본으로 제공하는 기능은 단순히 인스턴스의 참조값을 기반으로 작동하기 때문이다. 강의에서는 다음과 같이 세 가지 상황에서 어떤 결과가 나오는지 알아보았다.
- hashCode, equals를 모두 구현하지 않은 경우
- 데이터 저장 문제 : Object의 기본 기능을 사용해 인스턴스 참조값 기반으로 해시 코드를 생성했기 때문에 같은 id라도 다른 위치에 저장되어 중복 저장되는 문제 발생
- 데이터 검색 문제 : 데이터 검색 시 사용되는 해시 코드 역시 달라서 검색 실패
- hashCode는 구현했지만 equals를 구현하지 않은 경우
- 데이터 저장 문제 : hashCode() 재정의로 같은 id라면 같은 해시 코드를 사용, 그러나 중복 데이터 체크 로직에서 사용되는 contains()는 내부에서 equals()를 사용하므로 인스턴스의 참조값 기반으로 중복 체크
- 데이터 검색 문제 : contains() 내부에서 equals()로 비교하기 때문에 인스턴스 참조값을 비교하므로 검색 실패
- hashCode, equals를 모두 구현한 경우 : 같은 id라면 같은 해시 코드 사용, 중복 데이터 체크 성공, 검색 성공
✔️ 용어 정리
- 해시 함수 : 임의의 길이릐 데이터를 입력받아 고정된 길이(=저장 공간의 크기)의 해시 코드를 출력하는 함수.
- 해시 충돌 : 다른 데이터를 입력해도 같은 해시 코드가 출력되는 것.
- 해시 코드 : 해시 함수를 통해서 나온 결과로, 데이터를 대표하는 값.
- 해시 인덱스 : 해시 코드를 사용해 데이터의 저장 위치를 결정하는 값.
📘Set
Set은 중복을 허용하지 않고, 순서를 보장하지 않는 자료구조로, 빠른 검색이 가능하다!
실무에서는 주로 HashSet을 사용하며, 상황에 따라 LinkedHashSet(입력 순서 보장), TreeSet(데이터 값 기준 정렬)을 사용한다!
HashSet / LinkedHashSet / TreeSet 요약
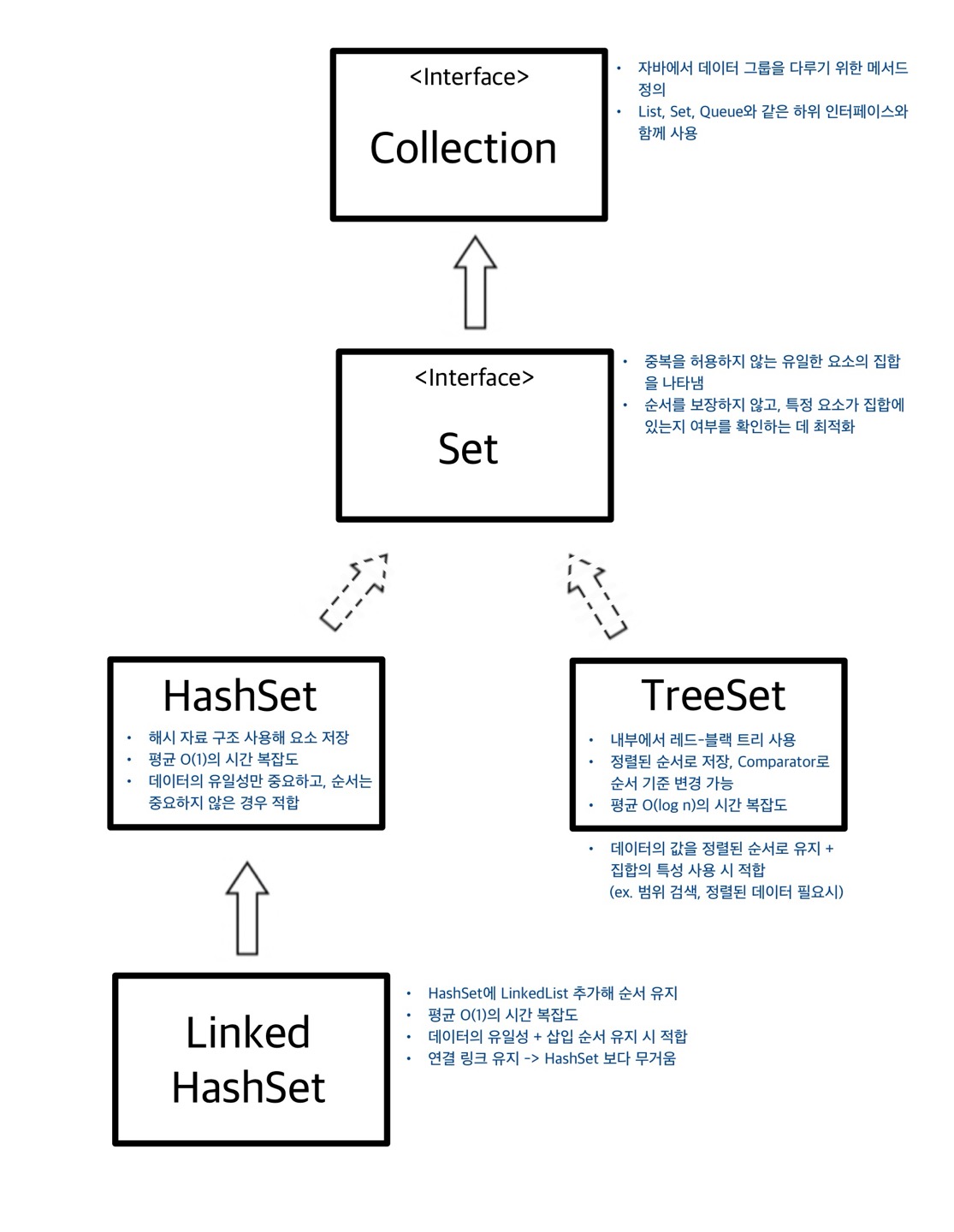
✔️ Set 인터페이스의 주요 메서드
- add(E e) : 지정된 요소를 세트에 추가한다.(이미 존재하는 경우 추가X)
- addAll(Collection<? extends E> c) : 지정된 컬렉션의 모든 요소를 세트에 추가한다.
- contains(Object o) : 세트가 지정된 요소를 포함하고 있는지 여부를 반환한다.
- containsAll(Collection<?> c) : 세트가 지정된 컬렉션의 모든 요소를 포함하고 있는지 여부를 반환한다.
- remove(Object o) : 지정된 요소를 세트에서 제거한다.
- removeAll(Collection<?> c) : 지정된 컬렉션에 포함된 요소를 세트에서 모두 제거한다.
- retainAll(Collection<?> c) : 지정된 컬렉션에 포함된 요소만을 유지하고 나머지 요소는 세트에서 제거한다.
- clear() : 세트에서 모든 요소를 제거한다.
- size() : 세트에 있는 요소의 수를 반환한다.
- isEmpty() : 세트가 비어 있는지 여부를 반환한다.
- iterator() : 세트의 요소에 대한 반복자를 반환한다.
- toArray() : 세트의 모든 요소를 배열로 반환한다.
- toArray(T[] a) : 세트의 모든 요소를 지정된 배열로 반환한다.
✔️ 재해싱(rehashing)
데이터의 양이 75% 이상일 경우, 배열의 크기를 2배 증가시키고 모든 데이터의 해시 인덱스를 커진 배열에 맞춰 다시 계산하는 과정. 자바는 재해싱을 통해 최적화 한다.
✔️ 이진 탐색 트리
- 이진 탐색 트리 : 한 노드의 왼쪽 서브 트리는 해당 노드의 값보다 작은 값을 가진 노드로 구성되고, 오른쪽 서브 트리는 해당 노드의 값보다 큰 값을 가진 노드로 구성된 트리
- 데이터를 입력하는 시점에 데이터의 값을 기준으로 정렬해서 보관
- 한 번 비교를 할 때마다 절반의 데이터만 남길 수 있음
- O(log N)의 시간 복잡도
- 최악의 경우 O(n)의 시간 복잡도
- TreeSet은 레드-블랙 트리를 사용해 균형 유지, 따라서 최악의 경우에도 O(log N)의 시간 복잡도
- 데이터를 차례로 순회하기 위해 중위 순회(왼쪽 서브트리 -> 현재 노드 -> 오른쪽 서브트리)
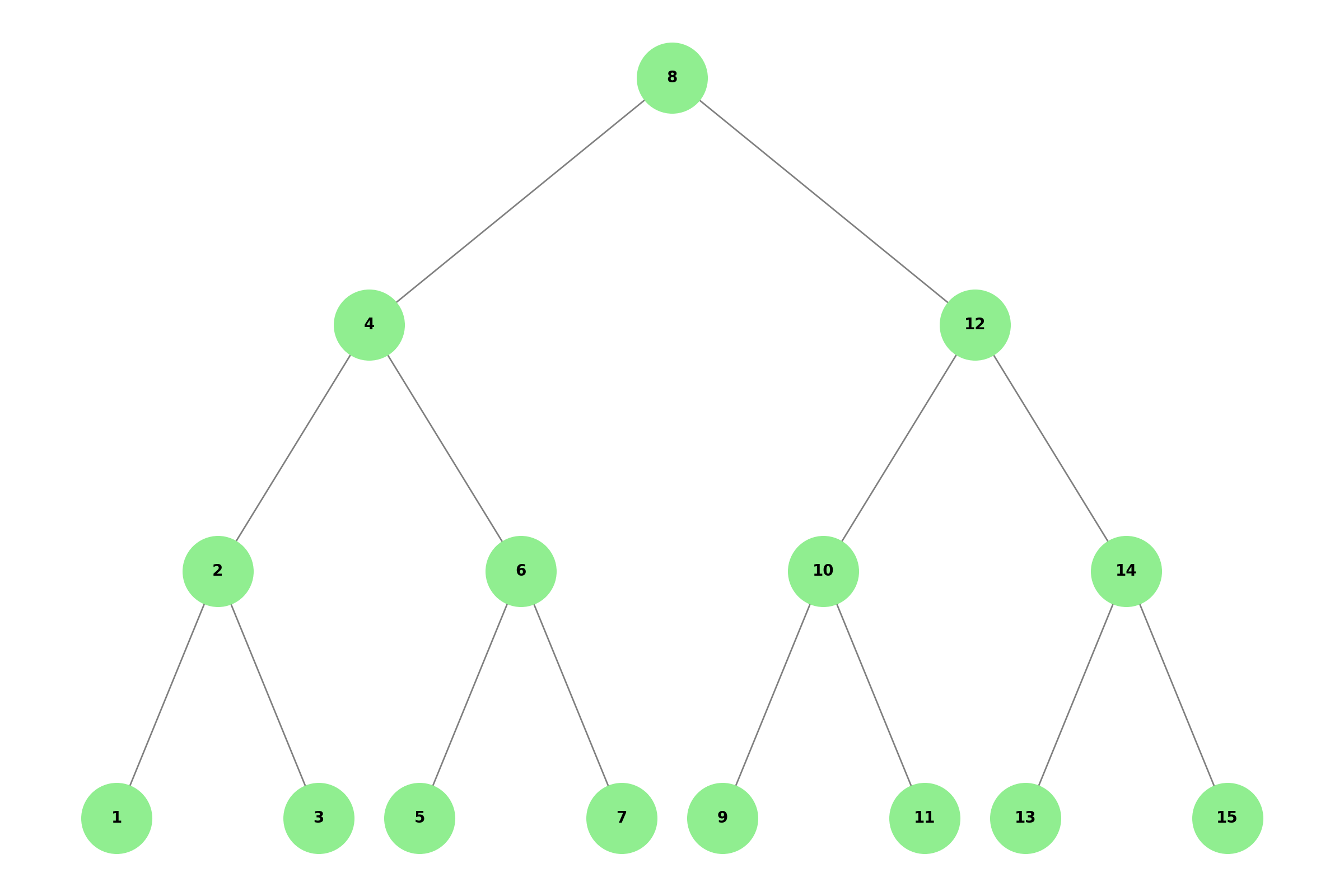
다음과 같이 트리가 불균형해지면 데이터 수만큼 검색을 해야한다. 따라서 최악의 경우 O(n)의 성능이 나온다.

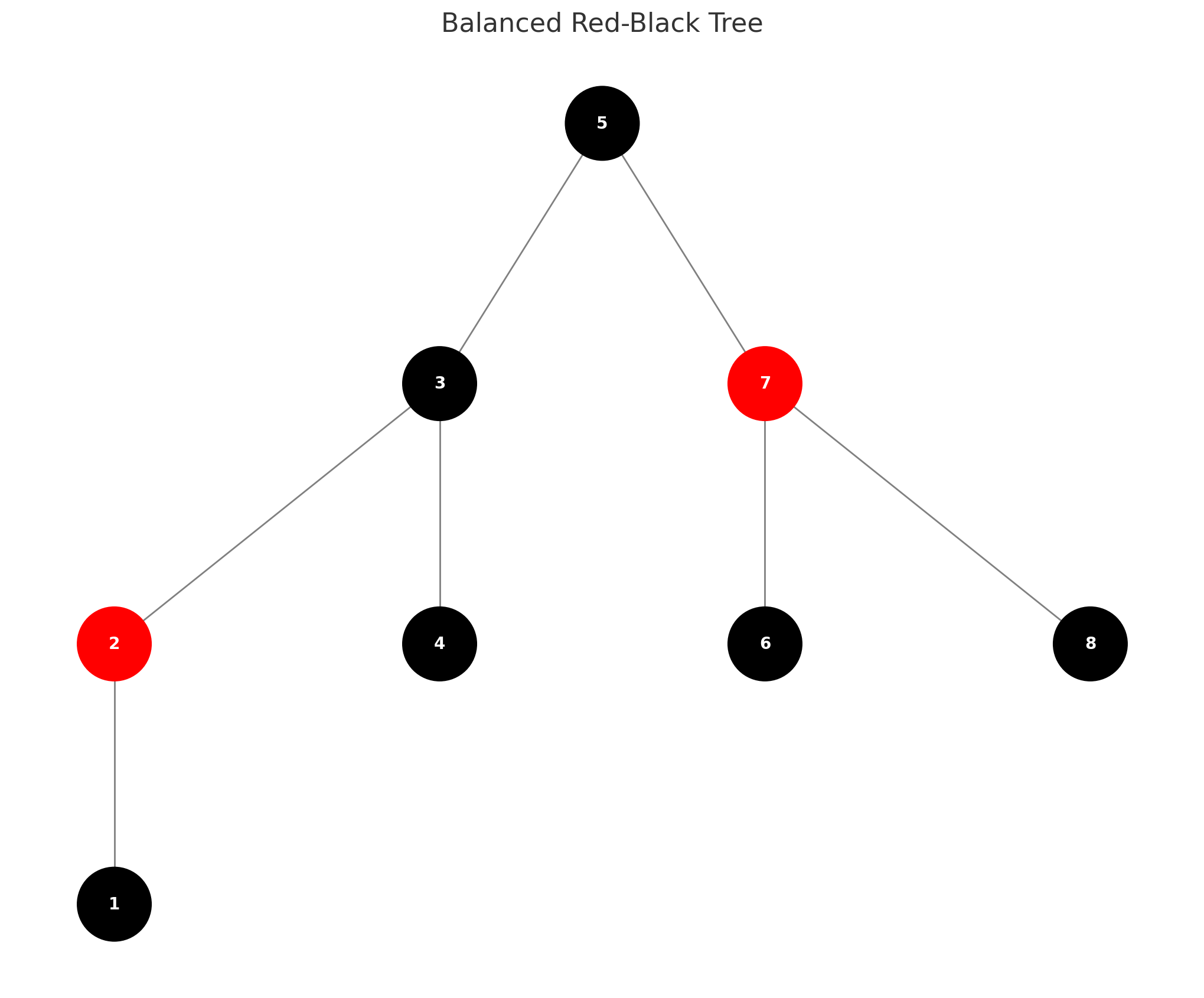
따라서 TreeSet은 불균형을 해결하기 위해 다음과 같이 레드-블랙 트리를 사용한다. 위의 불균형한 트리를 5를 기준으로 다시 정렬한 모습이다.
✔️ Set에 배열 편하게 넣기
Set 구현체의 생성자에 컬렉션을 전달할 수 있다.
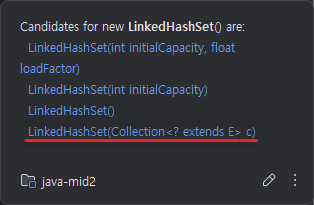
따라서 다음과 같이 Integer 배열을 List로 바꿔 생성자에 넣으면 바로 추가된다.
Integer[] inputArr = {30, 20, 20, 10, 10};
Set<Integer> set = new LinkedHashSet<>(List.of(inputArr));
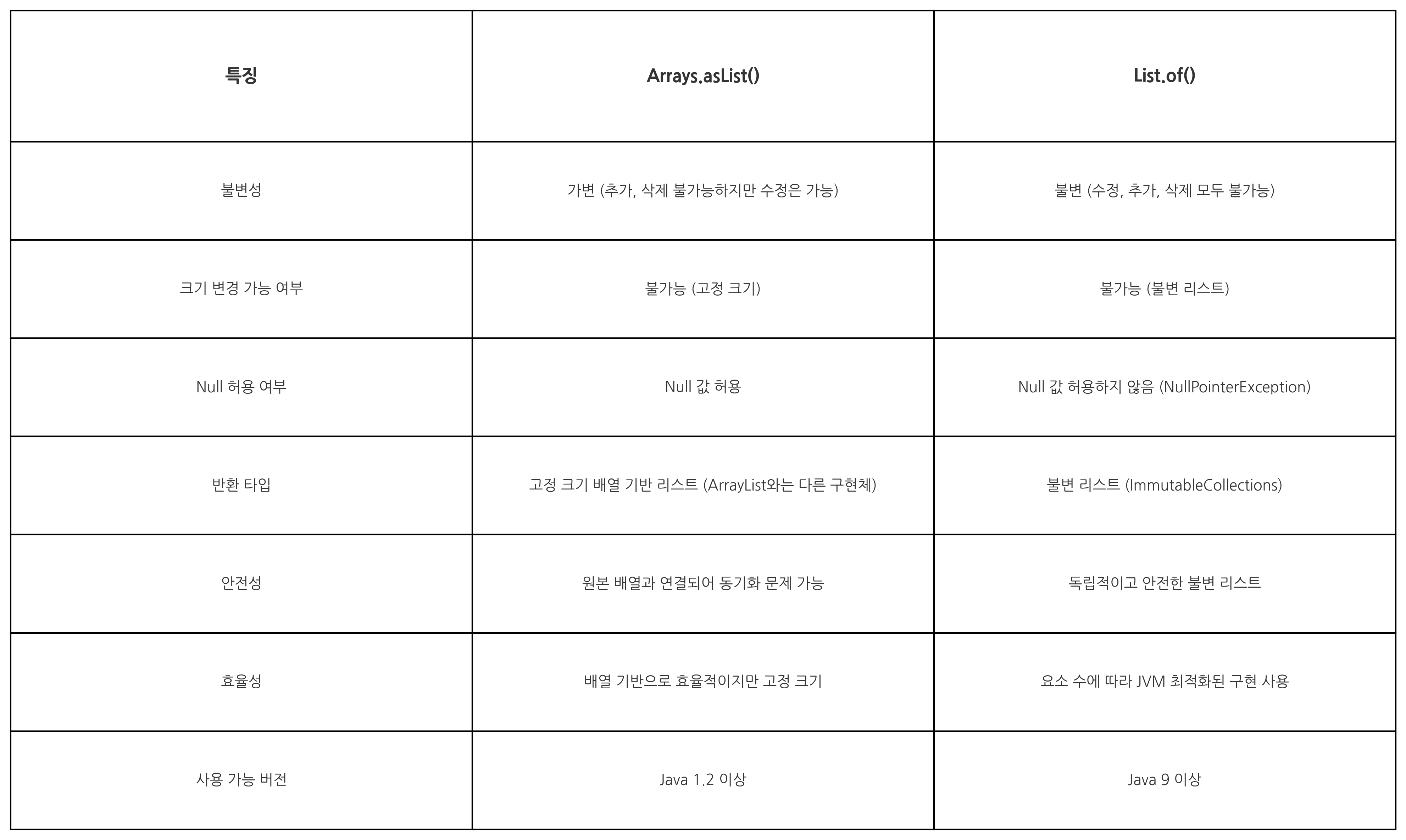
✔️ Arrays.asList()와 List.of()
Arrays.asList()와 List.of() 모두 자바에서 List 객체를 생성하는 데 사용된다. 자바 9 이상을 사용한다면 List.of()를 권장한다.
List.of()를 권장하는 이유가 궁금해 Arrays.asList()와 List.of()를 비교해보았다. List.of()를 사용하면 불변 컬렉션을 생성해서 데이터를 안전하게 보호할 수 있고, 가변 크기를 지원한다. 또한 내부적으로 더 효율적인 방식으로 동작한다고 한다. 가볍게 보고 넘어가자!
'Java' 카테고리의 다른 글
| [Java/Study] 김영한의 실전 자바 중급 2편 - 스터디 15회차 (0) | 2025.02.07 |
|---|---|
| [Java/Study] 김영한의 실전 자바 중급 2편 - 스터디 13회차 (0) | 2025.01.18 |
| [Java/Study] 김영한의 실전 자바 중급 2편 - 스터디 12회차 (0) | 2025.01.12 |
| [Java/Study] 김영한의 실전 자바 중급 2편 - 스터디 11회차 (0) | 2025.01.07 |
| [Java] 얕은 복사 vs 깊은 복사 - clone(), Arrays.copyof() (3) | 2025.01.02 |


